텍스트 입력을 기반으로 이미지를 생성하는 AI 개발
변환기 언어모델과 이미지 생성하는 확산 모델 결합
벤치마크 평가 결과, DALL-E 2보다 Imagen을 선호
편향성과 유해성 이유로 Imagen은 대중에게 비공개
구글이 텍스트 입력을 기반으로 이미지를 생성할 수 있는 새로운 인공지능(AI) 시스템을 선보였다. 구글은 '전례 없는 수준의 사실적 묘사와 깊은 수준의 언어 이해'를 통해 사실적인 이미지를 생성할 수 있는 텍스트-이미지 확산 모델(Diffusion Model)인 Imagen을 공개했다.
이런 AI 모델은 이번이 처음이 아니다. 오픈AI(OpenAI)의 DALL-E는 유사한 마술을 수행해 텍스트를 이미지로 바꾼다. 두 모델 모두 이미지가 텍스트 설명과 어떤 관련이 있는지 분류하기 위해 수많은 예제에서 훈련된 신경망을 사용한다. 새로운 텍스트 설명이 제공되면 신경망은 이미지를 반복적으로 생성해 학습한 내용을 기반으로 텍스트와 가장 근접하게 일치할 때까지 이미지를 변경한다. 그러나 구글은 보다 사실적인 이미지를 만들려고 한다.
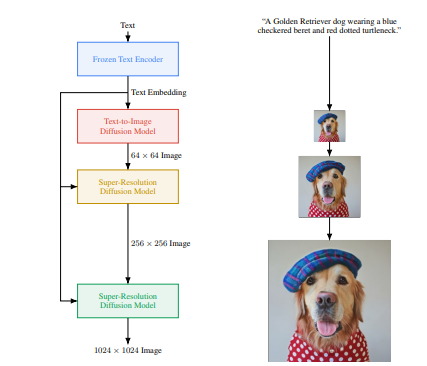
구글의 Imagen은 텍스트를 이해하는 대형 변환기(transformer) 언어모델의 성능을 기반으로 정확도 높은 이미지를 생성하는 확산 모델을 결합한다. Imagen을 통해 텍스트 전용 말뭉치로 사전 훈련된 거대한 언어모델의 텍스트 임베딩(embedding)이 모델 훈련에 이미지-텍스트 데이터만 사용하는 것보다 텍스트-이미지 합성(text encoding)에 효과적이라는 것을 발견할 수 있었다.
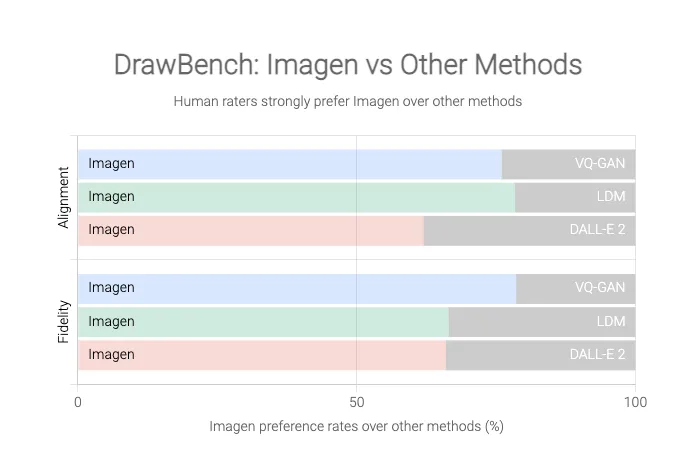
텍스트-이미지 모델을 보다 심층적으로 평가하기 위해 텍스트-이미지 모델에 대한 벤치마크인 DrawBench를 사용해 Imagen을 VQ-GAN+CLIP, Latent Diffusion Models 및 DALL-E 2를 포함한 최신 방법들과 비교한 결과, 평가자들이 다른 모델보다 Imagen을 선호한다는 것을 발견했다.

DALL-E와 마찬가지로 Imagen은 대중에게 공개되지 않는다. 구글은 여러 가지 이유로 일반 대중이 사용하기에 아직 적합하지 않다고 생각하고 있다. 한 가지 예로, 텍스트-이미지 모델은 일반적으로 웹에서 수집하고 선별되지 않은 대규모 데이터 세트에 대해 학습되므로 많은 문제가 발생할 수 있다.
텍스트-이미지 모델은 확실히 환상적인 창의적 잠재력을 가지고 있지만 문제가 많은 것이 사실이다. 예를 들어 가짜 뉴스, 속임수 또는 괴롭힘에 사용되는, 원하는 거의 모든 이미지를 생성하는 시스템을 상상해 보자. 구글이 지적했듯이 이러한 시스템은 사회적 편견도 인코딩하며 그 결과는 종종 인종 차별적이거나 성 차별적이거나 다른 방식으로 유해할 수 있다.
기본적으로 이러한 모델은 패턴을 연구하고 복제하는 법을 엄청난 양의 데이터에서 배운다. 이에 따라 엄청난 양의 데이터 입력이 필요하며 이 입력을 포괄적으로 필터링하는 것은 거의 불가능하다. 그래서 웹에서 엄청난 양의 데이터를 긁어 모았고 결과적으로 모델은 온라인에서 찾을 것으로 예상되는 모든 유해한 정보를 수집하고 복제하는 법을 배우게 된다.

이러한 데이터 세트는 사회적 고정관념, 억압적인 관점, 소외된 정체성 그룹에 대한 경멸적이거나 해로운 연관성을 반영하는 경향이 있다. 구글은 Imagen이 생성한 문제 콘텐츠에 대해 자세히 설명하지 않지만 모델은 "밝은 피부색을 가진 사람들의 이미지를 생성하려는 전반적인 편견과 성 차별적인 직업 이미지를 묘사하는 경향을 포함해 여러 사회적 편견과 고정 관념을 인코딩한다"고 밝혔다.
이것은 DALL-E를 평가하면서 발견한 것이기도 하다. 예를 들어 DALL-E에 ‘승무원’의 이미지를 생성하도록 요청하면 거의 모든 대상이 여성이 된다. ‘CEO’의 사진을 요청하면 놀랍게도 많은 백인 남성을 얻을 수 있다.
이러한 이유로 오픈AI는 DALL-E를 공개적으로 출시하지 않기로 결정했지만 일부 베타 테스터에게 액세스 권한을 부여하기도 했다. 또한 모델이 인종 차별적이거나 폭력적이거나 포르노 이미지를 생성하는 데 사용되는 것을 막기 위해 특정 텍스트 입력을 필터링한다. 이러한 조치는 이 기술이 유해한 응용 프로그램에 사용되는 것을 제한하는 데 어느 정도 도움이 되지만 언젠가는 공개될 것이 분명하고 광범위한 액세스가 가져오는 부작용을 피할 수 없을 것이다.
구글은 “Imagen은 현재 대중이 사용하기에 적합하지 않다"며 "향후 작업에서 사회적, 문화적 편견을 벤치마킹하고 반복적으로 테스트하는 새로운 방법을 개발할 계획이다”고 밝혔다.
AI타임스 박찬 위원 cpark@aitimes.com
무단전재 및 재배포 금지
기사제보 및 보도자료 news@aitimes.com