AI 모델 훈련과 처리, 확장 자동화하는 코드플레어(CodeFlare) 발표
파이프라인 분석 및 최적화 실행 시간 4시간에서 15분으로 단축
MS 애저 머신러닝 장단점 존재
IBM이 새로운 서버리스 프레임워크(Serverless Framework) 코드플레어(CodeFlare)를 발표했다. 기술매체 벤처비트(VentureBeat)가 7일(현지 시각) 관련 내용을 보도했다. (원문 링크)
서버리스란 개발자가 서버를 관리할 필요 없이 응용 프로그램을 설계 및 실행하는 클라우드 모델이다. IBM은 하이브리드 클라우드 환경에 배치할 AI 모델 준비 시간 단축을 위해 코드플레어 체계를 공식화했다. 개발자가 데이터 통찰에 집중할 수 있도록 AI 모델 훈련, 처리, 확장을 자동화한다는 것.
데이터와 머신러닝 분석의 확산에 따라 인공지능 연구를 위한 대규모 데이터셋과 시스템은 점점 복잡해지는 실정이다. 일례로 머신러닝 모델 생성을 위해서는 데이터 정리·표준화 등을 통해 모델을 훈련하고 최적화해야 한다.
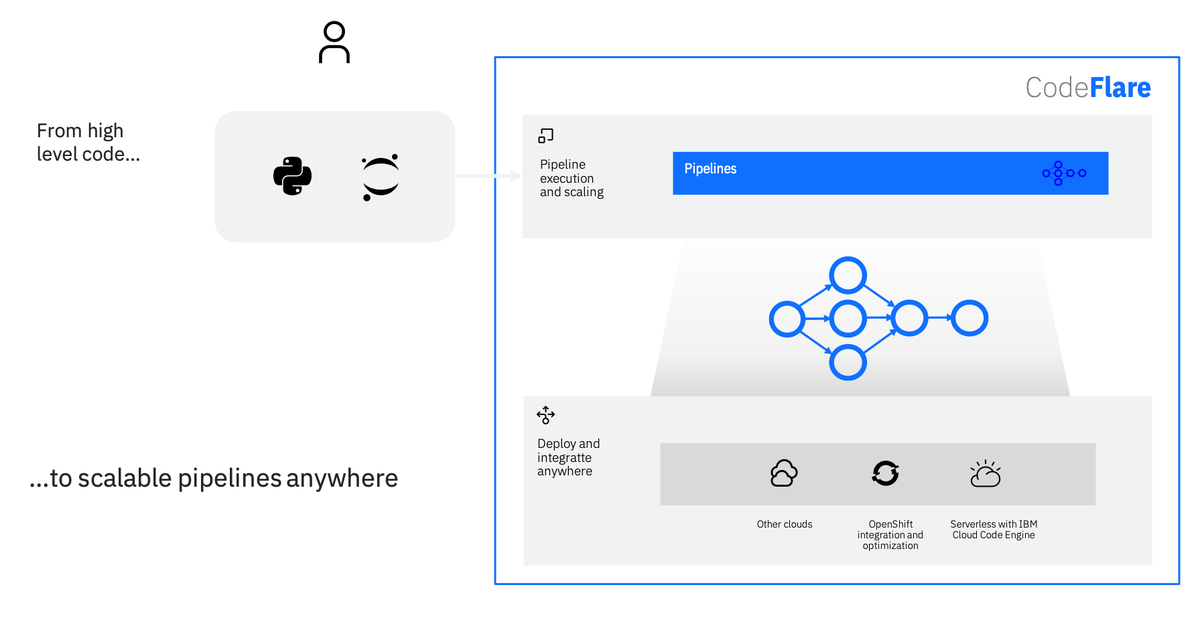
코드플레어는 데이터 워크플로우를 확장하는 특정 요소로 반복 과정을 단순화하고자 한다. AI 개발 환경 구축에 소요되는 시간을 줄이겠다는 취지다. 미국 UC 버클리대학 라이즈 랩(RISE Lab)의 AI 애플리케이션용 오픈 소스 분산 컴퓨팅 시스템 레이(Ray)를 토대로 구축했다.
코드플레어는 여러 플랫폼의 파이프라인을 관리하기 위해 파이썬(Python) 기반의 인터페이스를 제공한다. 파이프라인은 한 데이터 처리 단계의 출력이 다음 단계의 입력으로 이어지는 형태로 연결된 구조를 의미한다. 어댑터를 통해 대부분의 컴퓨팅 환경에서 병렬화 및 공유할 수 있을 뿐 아니라 다른 클라우드 네이티브(Cloud-native) 시스템과 통합할 수 있다.
코드플레어의 트리거 기능은 새 파일이 도착하는 등 특정 사건이 발생했을 때 파이프라인을 자동 실행한다. 또, 데이터 로딩과 분할 지원을 통해 파일 시스템ㆍ객체 스토리지ㆍ 데이터 레이크 및 분산 파일 시스템을 비롯한 다양한 데이터 소스를 끌어낼 수 있다.

IBM은 코드플레어가 10만 개의 훈련 파이프라인 분석 및 최적화 실행 시간을 4시간에서 15분으로 단축할 수 있다고 밝혔다. 현재 오픈 소스로 제공 중이며, 작동 방식과 개발자를 위한 가이드라인 등 일련의 블로그 게시물을 게재했다. 코드플레어를 지속적으로 발전시켜 결함 허용성 및 일관성ㆍ외부 소스에 대한 통합 및 데이터 관리ㆍ파이프라인 시각화 지원과 같은 복잡한 기능을 지원할 계획이다.
클라우드 대시보드에서 머신러닝 파이프라인의 흐름을 자동화ㆍ체계화하는 아마존 세이지메이커 파이프라인(Amazon SageMaker Pipeline)은 코드플레어와 유사한 특징을 갖는다. 또, 구글과 마이크로소프트, 하이버넷 랩스(Hybernet Labs)는 각각 클라우드 AI 플랫폼 파이프라인(Cloud AI Platform pipelines), 애저 머신러닝 파이프라인(Azure Machine Learning pipelines)과 갈릴레오(Galileo)에서도 유사 서비스를 제공 중이다.
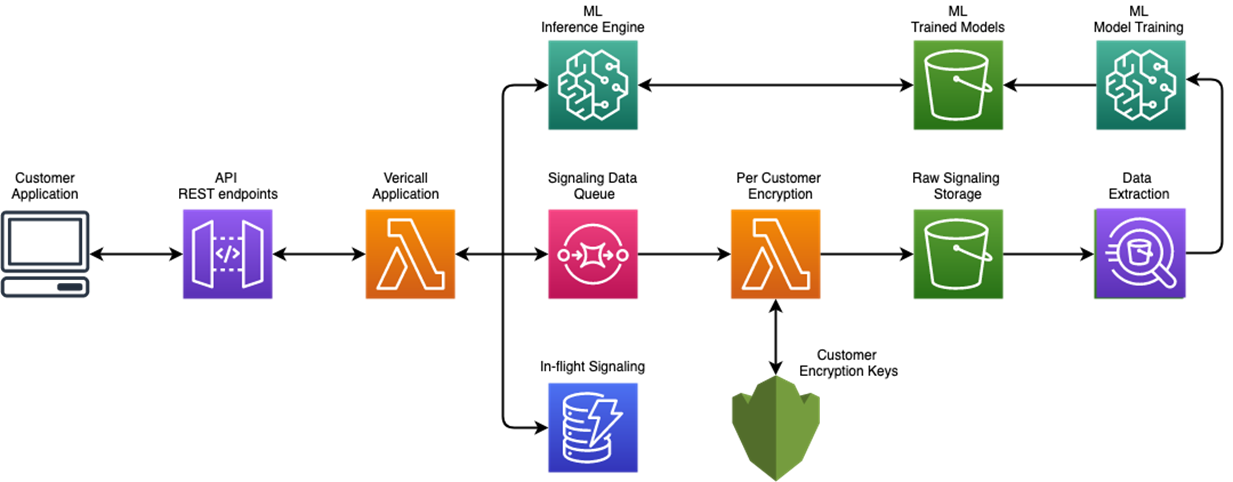
아마존 세이지메이커 파이프라인은 머신러닝에 특화되고 사용이 간편한 지속적 통합/지속적 전달(CI/CD) 서비스다. 해당 기능을 통해 사용자는 엔드투엔드 머신러닝 워크플로우 각 단계를 정의할 수 있다. ▶데이터 로드 단계 ▶아마존 세이지메이커 데이터 랭글러(Amazon SageMaker Data Wrangler)로부터 변환 ▶아마존 세이지메이커 피처 스토어에 저장된 피처, 훈련 구성 및 알고리즘 설정 ▶디버깅 단계 ▶최적화 단계 등이 포함된다. 워크플로우가 실행될 때마다 각 단계를 기록하므로 개발자는 머신러닝 모델 반복, 훈련 파라미터와 결과를 시각화 및 비교할 수 있다.
마이크로소프트 애저 머신러닝 파이프라인(Azure Machine Learning pipelines)은 사용자와 컴퓨터 간 상호작용을 돕는 드래그 앤 드롭 평가 방식의 파이프라인을 보유하고 있다. 사용자는 개인의 파이썬이나 R 모듈을 데이터 파이프라인에 추가할 수 있다. 애저 머신러닝 스튜디오의 구성은 ▶수십 종의 데이터셋 표본 ▶다섯 종의 데이터 형식 변환 ▶수십 가지 데이터 변환 ▶세 가지 기능 선택 방식 등으로 이루어진다.
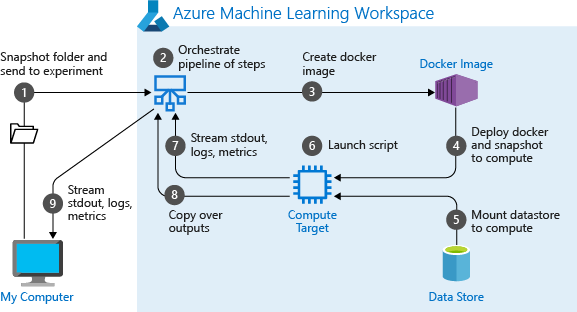
테크 미디어 CIO 코리아(CIO Korea)의 마틴 헬러(Martin Heller)는 ‘MS 애저 머신러닝 리뷰 : 기대되는 전문가용 머신러닝 서비스’라는 제목의 기사에서 해당 서비스를 분석 및 평가한 바 있다. 그는 “통상 데이터 기획과 간단한 탐색 통계 작업을 출발점으로 삼는다. 그리고 데이터를 적용, 부합하는 모델과 데이터 변환 방식을 찾는다. 애저 머신러닝 스튜디오(Azure Machine Learning Studio)는 이런 기능들을 지원하지 않는 것으로 보인다”며 아쉬움을 드러냈다.
한편, “애저 머신러닝에 어느 정도 통합되어 있는 아나콘다 파이썬(Anaconda Python)ㆍ주피터 노트북(Jupyter Notebooks)ㆍ R 서버에 탐색 데이터 분석 기능이 존재한다. 애저 머신러닝 스튜디오만으로 필요한 것을 처리할 수 있을지 모른다”며 긍정적인 측면을 언급하기도 했다.
AI타임스 박유빈 기자 parkyoobin1217@aitimes.com
무단전재 및 재배포 금지
기사제보 및 보도자료 news@aitimes.com